
Nous sommes en 2026, vous êtes encore développeur, bonjour.
Ces 6 derniers mois j'ai vraiment rincé Claude Code.
De la ré-écriture complète du site de la billetterie de Devoxx France, à la création d'un moteur de jeux de rôles, en passant aussi par mon travail pour proposer cet outil aux développeurs de Back Market... il s'en est passé des choses.
Je pense qu'en 2026, la majorité du code que j'écrirai sera générée à l'aide d'un outil de GenAI comme Claude Code ou Codex CLI. Je ne sais pas pour vous... mais moi la partie purement "saisie de code" ne m'intéresse plus. Cela n'enlève pas le temps de la réflexion, de l'analyse, de la relecture du code généré. Cela me retire simplement la partie purement dactylographique de mon métier. Je tape vite au clavier, mais j'ai trouvé plus rapide.
Entre mes premiers petits tests en mai 2025 et aujourd'hui, j'ai testé de nombreux outils. Même si je parle beaucoup de Claude Code, j'ai aussi testé Cursor, Codex CLI, Mistral Code, Charm Crush, etc. Et Claude Code lui-même évolue rapidement, comme vous pouvez le constater ici. Le modèle sous-jacent est important, mais le code de l'agent est tout aussi important. J'ai testé Crush avec le même modèle d'Anthropic, et des résultats assez différents. L'UX de Crush est magnifique, mais Claude Code est une machine de guerre hautement efficace.
Si vous n'êtes pas encore prêt (ou remplacé) pour (par) Claude Code, vous pouvez commencer par les tests. C'est bien ça, les tests. Cela donne une solide fondation à votre code, vous n'aimez pas les écrire (et les maintenir) et les outils de génération de code sont très performants. Au passage, écrire des tests unitaires, fonctionnels, ou de recettes, aident énormément les outils de GenAI, et sont de solides fondations (et aussi de la doc) pour éviter les surprises (et les hallucinations, mais ça je vais en parler tout à l'heure) .
Claude Code sait coder. Mais il sait aussi utiliser votre navigateur (avec votre permission) via des outils MCP comme Chrome dev-tools ou Browser MCP.
Chrome Dev-Tools est mon outil MCP préféré mais ne fonctionne qu'en mode incognito, donc compliqué avec de l'OAuth. Browser MCP utilise une extension dans votre navigateur Firefox ou Chrome, et donc dispose de la capacité d'accéder à des pages protégées. C'est ultra pratique pour analyser des bugs en préproduction.
Claude Code sait aussi lire des logs, ou se connecter à Datadog en lecture seule. Cependant, attention à ne pas laisser activer en permanence plusieurs outils MCP. Cela utilise des tokens de votre fenêtre de contexte, augmente le coût et devient contre-productif lorsque votre session n'a rien à voir avec Datadog (par exemple). De même, j'ai arreté d'utiliser Playwright MCP. Trop gourmand, les tests ne passent pas forcément. Je préfère laisser Chrome dev-tools se coordonner avec l'exécution de playwright par Claude Code. Cela coûte moins de token et c'est plus simple.
L'IA est aussi un outil qui aide énormément à analyser/comprendre/documenter du code legacy. J'imagine que nous serons bientôt capables de refactorer un gros monolithe en deux/trois semaines, là où cela aurait demandé des mois (des années) il y a 2 ans.
Mais tout ceci va aussi changer notre façon de coder, voire même de développer des applications dans le futur.
Assis toi, arrête de prendre des screenshots de ce post et écoute moi 2 secondes.
La majorité du code écrit en 2026 sera rédigée à l'aide d'outils de Gen AI. D'ici un an, je ne vois pas pourquoi nous continuerons à écrire du code, alors que les outils dont nous disposons, serrons capables de le faire mieux, plus simplement et sans fatigue, sans erreurs.
Car oui, les outils de GenAI hallucinent (parfois) mais sont en général sacrément meilleurs que toi ou moi.
Ces outils cependant, n'ont pas de mémoire. Faites l'expérience d'effacer le fichier CLAUDE.md, reprenez un vieux prompt, et constatez les dégâts. Retirez tous vos tests unitaires, effacez la documentation de votre projet (car la VRAIE doc c'est le code... yolo)... et constatez les dégâts. Cela va prendre plus de temps, l'outil va chercher à converger et va perdre du temps à analyser des fichiers textes sans comprendre la valeur et ce qu'il doit faire... autant laisser un développeur Java sur une code base en Ruby.
La documentation est primordiale pour que les outils de génération de code basés sur des LLMS soient efficaces.
Vie ma vie de contributeur
J'ai fait une pull request récemment. J'utilise Claude Code pour traiter un cas particulier, assez difficile à identifier en lisant le code. Après avoir vu Claude Code ajouter le test, compléter le code, et ajouter de la doc, je me dis en effet qu'il serait pertinent d'ajouter un peu de documentation dans le code (sous la forme de commentaires). Au passage c'est pas mal pour le prochain Claude Code Stagiaire qui relira ce même code. Bref, je crée la PR, je la push. Elle est reprise par l’un de mes collègues, qui la valide, mais retire la doc ajoutée par Claude Code. Il a conservé uniquement le code et fusionné ladite pull request. Je l'ai contacté, un peu étonné.
- "Bah pourquoi tu as retiré les commentaires dans le code ?"
- "cela ne sert à rien, on comprend bien en lisant toute la fonction"
- "... en effet. Mais si ce code est relu par un outil comme Claude Code, ne penses-tu pas que cela éviterait de devoir analyser toute la fonction ? Et donc de consommer plus de tokens ? Et donc d'impacter la couche d'ozone car beaucoup de tokens, c'est du CO2 ?
- ah mince...
Bon pour la partie sur le CO2, désolé, je trolle (vas-y prend un screenshot de celle-là)
Je ne dis pas qu'il faut soudainement ajouter des tonnes de commentaires dans le code. Mais j'ai constaté qu'il devenait de plus en plus important de garder de la documentation sur ce qui a été fait lors d'une grosse session. Cela change ma façon de coder. Je ne faisais pas cela "avant".
Aujourd'hui je créé un répertorie "ai/" que je versionne avec mon projet. Ce répertoire contient un dossier par activité/session importante. Exemple : j'ajoute le paiement par CB sur reg.devoxx.fr. Comment ai-je procédé ? J'ai créé un folder "ai/payment" dans lequel j'ai demandé à Claude Code de me documenter à priori et à posteriori ce qu'il avait fait.
Voici à quoi cela ressemble :
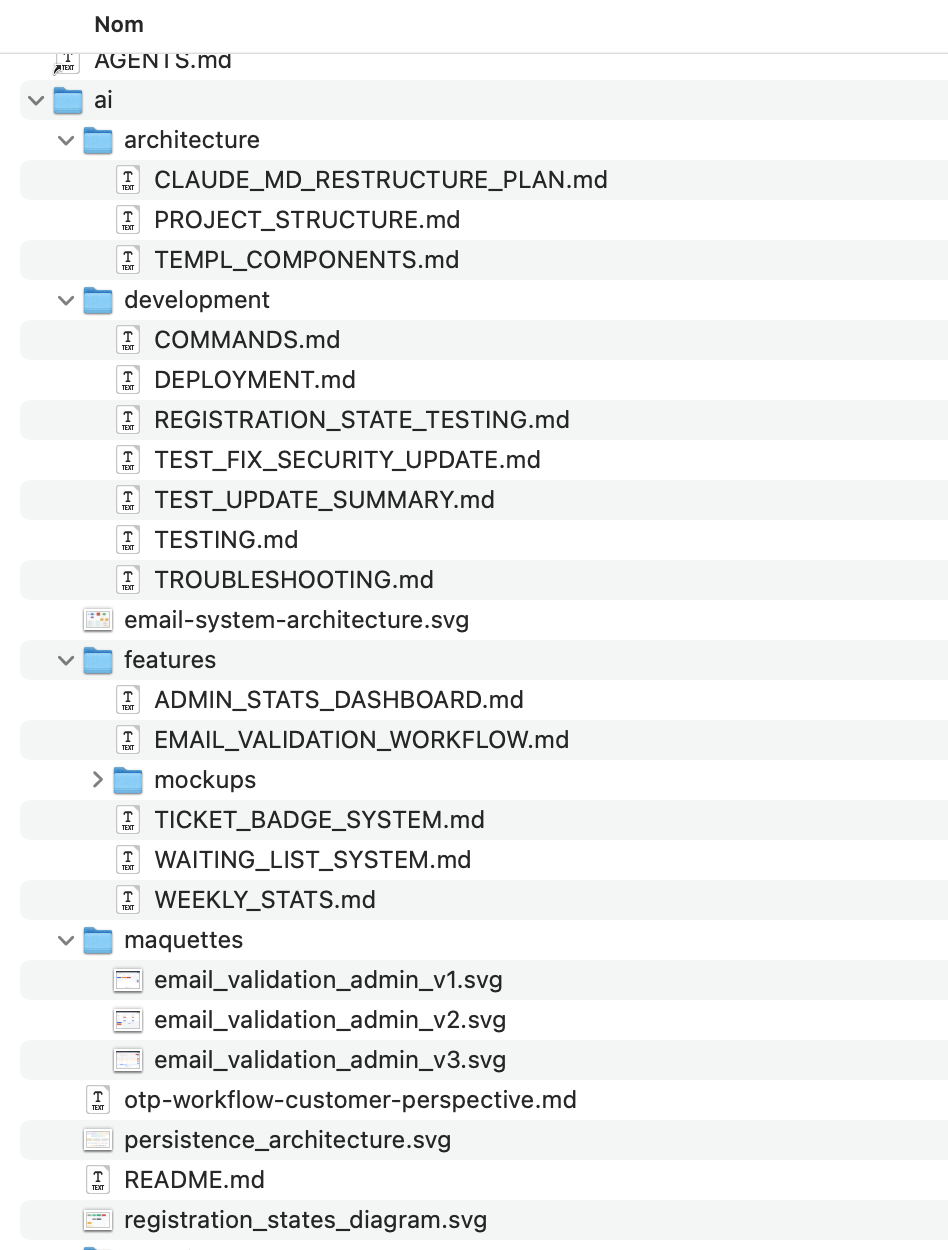
Vous pouvez constater que j'ai gardé mes maquettes SVG de chaque écran, créés via Claude Code AVANT de générer mes templates HTML. Toute l'architecture, les diagrammes, les éléments importants sont stockés dans des fichiers Markdown. Je n'ai pas bourré mon fichier CLAUDE.md car cela consomme trop de Tokens inutilement (et ça pète du CO2, essayez de suivre :troll). Je m'en suis resservi dans des cas d'améliorations, en expliquant à Claude Code qu'il pouvait aller piocher l'historique de ce qui a été fait dans tel ou tel fichier.
Cela s'appelle des spécifications. Je sais, vous n'étiez pas prêts.
On va écrire/générer beaucoup plus de documentations car la qualité d'un outil de GenAI comme Claude Code dépend à mort de la documentation du projet. Notez qu'un fichier SVG se parse avec Claude Code (c'est du texte), sans devoir passer par un PNG. Vectoriel/Bitmap, toussa... Bref

Comment Cursor ou Claude Code peuvent éviter d'halluciner ?
J'ai dépensé (investi) plus de 900 $ entre septembre et décembre pour ré-écrire complètement la billetterie de Devoxx France. J'ai complètement changé ma façon de prompter entre juillet et septembre. Au début "je ne savais pas prompter". Et soyons réaliste : il m'a fallut dépenser pas mal de tokens, pour apprendre à prompter correctement.
Là normalement cher lecteur, je t'envoie vers un site et tu achètes ma formation sur "comment prompter comme un boss" à $899 mais pas de ça ici, on va te filer les secrets gratuitement.
Claude Code c'est un outil. Copilot c'est un outil. Cursor c'est un outil. Toi tu es un ouvrier. Tu utilises l'outil. Le cerveau c'est toi. Lui il est bête à manger du foin. Il n'est pas Intelligent. Si tu parles English, Artificial Intelligence c'est un faux ami. Intelligence en Anglais devrait être traduit en "Connaissance". Mais comme nous sommes tous des quiches en Anglais, voilà "Intelligence Artificielle" au 20 heures, laissez passer les experts (coucou Luc Julia).
Si l'outil hallucine c'est qu'il cherche à tout prix une solution. On appelle cela converger. Sur Google si tu t'amuses à taper n'importe quoi, il est presque certain que tu auras un résultat, qui n'a rien à voir, mais tu auras un résultat. Les outils de GenAI c'est pareil. Et en plus, ils tendent à te flatter, à s'excuser et à utiliser de ce que l'on appelle en bon français de la "flagornerie".
Je peux placer Sycophantic dans cet article ? Flegme.
Lorsque j'ai une tâche à faire, voici comment j'évite les hallucinations :
- je prépare un plan, et je demande à Claude Code (ou ChatGPT) d'améliorer ce plan
- j'utilise le mode "Plannification" et je vérifie l'approche, répond à quelques questions, et je m'assure que ma demande initiale est précise
- lorsque je vois que le résultat n'est pas satisfaisant, je discute avec Claude pour crafter mon prompt. Je ne lui demande pas de commencer à faire quoique ce soit... mais à bosser sur mon prompt
- je tend aussi à garder mes prompts complexes sous la forme de fichiers Markdown dans mon répertoire "ai/" pour pouvoir revenir dessus
- je vérifie la liste des outils MCP activés. Je désactive ce qui ne me sera pas utile
- je prend un modèle plus puissant comme Opus pour plannifier et je passe avec Haiku pour l'implémentation
- je me couche tôt le soir et je dors 8 heures, sinon ben je suis fatigué et je fais n'importe quoi
- je ne laisse pas l'outil "devinez" ou "trouver tout seul" car cela me fait perdre du temps, il peut trouver n'importe quoi
- je regarde comment les autres promptent, je parle avec des humains
- je n'oublie pas que l'outil est bête, et que si le résultat est explosé au sol c'est que le problème se situe entre le clavier et la chaise
Voici à titre d'exemple un prompt que j'ai envoyé pour m'assurer que les adresses emails avec un "+" soient gérées sur le site reg.devoxx.fr
Je souhaite vérifier si les adresses emails avec un "+" sont correctement gérées. Pour cela je viens de créer une nouvelle inscription 388-HUT-HQEA-533. Utilise un outil MCP pour aller sur http://localhost:8026/ et charger l'email "Confirmation d'inscription" lié à cette inscription. Copie le lien de validation que tu trouveras dans le mail pour le charger sur http://localhost:8080 au lieu de https://reg.devoxx.fr. Cela doit charger la page "http://localhost:8080/validate/challenge?email=user+devoxx@gmail.com&code=388-HUT-HQEA-533".
Observe d'abord que l'email affiché ne montre plus le signe "+" sur la capture d'écran [Image 1]. Ensuite, le mail "Envoyer le code maintenant" n'utilise pas la bonne adresse email, comme tu le verras sur Mailhog à nouveau. Corrige ces bugs. Assure-toi avec des tests que cela ne fonctionne pas AVANT de corriger le souci, puis corrige le souci et verifie APRES.
Claude Code se lance alors, je le vois bosser, et pendant ce temps-là, je fais autre chose. Cela va me coûter $2.90.
Tous les tests passent.
Résumé de la correction
Le bug
Les adresses email contenant un + (comme user+devoxx@gmail.com) étaient mal gérées :
- Le + dans l'URL était interprété comme un espace
- L'email affiché devenait user devoxx@gmail.com (sans le +)
- Les emails OTP étaient envoyés à la mauvaise adresse
La cause
À la ligne 97 de handlers.go, l'email était concaténé directement dans l'URL sans encodage :
c.Redirect(http.StatusFound, "/validate/challenge?email="+payload.Email+"&code=...")
La correction
1. Ajout de net/url dans les imports
2. Création de BuildValidationChallengeURL : fonction helper qui encode correctement l'email avec url.QueryEscape()
3. Modification de la redirection pour utiliser cette fonction
Fichiers modifiés
- internal/handlers/validation/handlers.go : ajout de l'encodage URL
- internal/handlers/validation/handlers_test.go : nouveau fichier de tests
Résultat
- L'URL contient maintenant email=user%2Bdevoxx%40gmail.com (avec %2B pour le +)
- L'email s'affiche correctement : user+devoxx@gmail.com
- Les emails OTP sont envoyés à la bonne adresse
Cela va ajouter 1900 lignes, retirer 270 lignes et donc le tout pour $2.90.
J'ai changé ma façon de travailler, et les outils changent la façon de coder. C'est indéniable.
It's only the beginning...
Pour paraphraser Stan mon ancien CEO : ce n'est que le début. Nous sommes dans les 2/3 premières années de l'arrivée de ces outils.
Côté modèle, même si Anthropic écrase un peu la concurrence, il faut surveiller et ne pas hésiter à tester avec Claude Code.... d'autres modèles. Par exemple CC-Mirror permet de tester avec Z.ai avec GLM 4.7, MiniMax ou OpenRouter.
Si vous voulez voir en temps réel un classement des différents LLMs, je vous recommande https://llm-stats.com/arenas (lorsque le site marche) et plus intéressant, un classement du nombre de tokens utilisés sur OpenRouter. Les plus sérieux me semblent être les classements d'Artificial Analysis. Le plus pragmatique (faire faire une tâche identique par différents LLMs) est CodeClash. Bref fouillez, soyez curieux et testez :-)
Vous pouvez aussi pimper votre expérience avec Claude Code via TweakCC, qui permet d'améliorer le terminal, de sauvegarder des sessions avec un nom.
Bref, je suis personnellement convaincu que la GenAI a déjà changé notre façon de coder. Pas notre passion, ni le plaisir de créer une fonctionnalité. Il a simplement retiré la partie purement "saisie" du code. Je m'amuse toujours autant à tester des idées, à envisager 2 ou 3 façons de résoudre un problème et à découvrir ensuite le résultat après quelques minutes.
Passez une bonne année 2026 !

Bonjour,
Je partage assez cet avis, je suis un ancien resté dans la tech et l'IA Gen a révolutionné mon métier (infra cloud et toujours un peu de dév).
Mais le danger réside aussi dans l'introduction d'une forte dépendance en ces outils.
Hormis le coût d'usage, quid du jour où l'outil est indisponible ou devient trop coûteux?
Je travaille dans l'évaluation et la mise en place d'outil IA au sein de mon entreprise, et cette dépendance croissante ainsi que le brain-rot que je constate déjà m'inquiètent vraiment.
Tout cela est passionnant mais quid du cout ?
En effet aujourd'hui nous sommes en phase de montée en puissance de l'IA générative et les boites US veulent prendre un max de part de marché, d'où les prix bas.
Mais lorsque la consolidation du marché viendra, et que les financiers vont vouloir récupérer leur mise, ces boites n'auront d'autres choix que d'augmenter les prix.
Pour le coup, ca va devenir un problème
Un autre aspect que j'ai remarqué et que tu l'as très bien dit, c'est que pour avoir un code de qualité, il faut être ultra précis, limite très verbeux sinon l'IA commence à faire n'importe quoi et on perd beaucoup de temps dans les cycles de correction.
Pour quelqu'un qui a l'habitude de coder régulièrement, je me demande quel serait le ration de gain entre:
1. Coder soi meme avec assistance syntaxique (IntelliJ de base propose des choses assez sympas)
2. Coder soi meme avec assistance LLM pour aller plus loin que le point précédent
3. Ne plus coder mais prompter très précisément ses besoins
Salut , ton article est super intéressant, j'ai effectivement utilisé deja (un peu) Copilot, et au printemps dernier Windsurf AI. Mais pas encore Claude Code, du coup en te laisant cela me donne envie de l'essayer.
Par contre , quand tu. dis "Je pense qu’en 2026, la majorité du code que j’écrirai sera générée à l’aide d’un outil de GenAI comme Claude Code ou Codex CLI. " je pense que (1) c'est ton avis (2) de mon coté, en recherche d'emploi en ce moment, et au regard des offres, je ne vois aucune précision sur de la programmation assistée par l'IA. Du coup je crois deviner que globalement dans les entreprises, on faie encore de la pure "saisie" de code comme tu dis, enfin je crois. J'ai l'impression, et cela parce que j'ai eu quelques discussion avec des ex collègues, que les entreprises sont encore en train d'hésiter, deja sur les outils et les modéles (copilot, cursor, codex, Claude Code), et pas forcément non plus convaincus d'aller sur le "vibe coding". Un collègue , dans une grande entreprise, me dit qu'ils sont encore plus ou moins en phase de test, et je ne pas crois pas qu'ils sont pret a partir sur de la generation de ready code pour la production avec une IA. Cela change pas mal de façon de travailler deja pour le développeur, ensuite surement coté équipe , du genre moins de développeurs du coup, pratiquement que des expérimentés et des seniors pour valider le code, debugguer, tester. D'une façon générale, je ne sais pas la proportion des sociétés qui developperont avec assistance IA en 2026, ainsi que les sociétés qui développent ainsi depuis 2025. Voila ou j'en suis. Je suis conscient que de toute façon le métier de dev va changer et va aller vers l'IA pour programmer (un jour..quand exactement je sais pas...2026 voire 2027). Voila, pour l'instant je continue mes investigations et tests sur le sujet. Merci de cet article par rapport a ton experience avec Claude code mode CLI (je crois si j'ai tout compris). Continue a poster ce genre d'article dans le futur, avec tes nouvelles découvertes et aussi en fonction de l'évolution des outils autour (de Claude notamment, si tu continues avec Claude Code..Mais ca va vite, aujourd'hui c'est Claude, Google a sorti récemment (Gemini Code Assist je crois).
Salut,
Discussion très intéressante. Effectivement, l'IA offre des possibilités fabuleuses, un peu magiques, qu'il serait stupide d'ignorer, mais la difficulté est d'apprendre à l'utiliser intelligemment :
- bien déterminer les rôles et tâches qu'on veut lui attribuer
- garder la maîtrise du code ou au minimum de sa logique
- savoir lui fournir ce dont elle a besoin (contexte, documentation)
- comprendre comment formuler nos prompts, analyser ses réponses et l'orienter
- utiliser les outils appropriés (MCP)
- éviter les eccueils
Selon ma modeste expérience, je considère l'IA comme un assistant, d'intelligence supérieure si je lui explique tout dans le détail sans le noyer d'informations. Je lui fournis les informations en markdown de la manière la plus précise, structurée et synthétique possible. Je lui demande parfois s'il a des questions avant de me répondre. Je me suis auto-promu chef de projet.
J'ai un abonnnement copilot, qui permet d'utiliser de nombreux models. Claude est indéniablement le meilleur jusqu'ici. GPT (GTP 5.2, codex, codex plus) sont verbeux et ont tendance à mettre des pansements sur des jambes de bois.
Je travaille avec vscode, un dossier .github qui permet de créer des agents personnalisés et des instructions.
J'ai donc :
- un dossier .github/agents/ qui contient différents agents selon les besoins
- un dossier .github/instructions/ qui contient un fichier général et des fichiers spécifiques que l'IA consultera en fonction des langages de programmation utilisés.
Pour les agents, instructions, prompts, etc, voir ici, c'est une mine d'or : https://github.com/github/awesome-copilot
Question rôles et compétences : je garde la main sur tout ce que je maîtrise, et oriente l'IA pour qu'elle fasse exactement ce que je veux lorsqu'elle peut le faire plus vite|mieux que moi. Par exemple rédiger une regex, utiliser une API, mette en place des unit tests, et plein d'autres choses.
l'IA sait aussi faire beaucoup de choses pour lesquelles je n'ai pas les compétences. Je n'utiliserai jamais ces capacités dans un projet dont je dois garder la maîtrise, ou au minimum la compréhension. Mais par exemple lorsque récemment j'avais des questions juridiques (rien à voir avec mon travail de programmeur) et que je n'ai rien trouvé pour m'aider, j'ai utilisé intégralement l'IA pour concevoir un serveur MCP qui utilise l'API legifrance.
Couplé à un bon fichier d'instructions ("utilise systématiquement le MCP, cite précisément les textes de lois, ...") ça fait des merveilles.
Je ne suis pas convaincu par l'utilisation de tout ces prompts. Depuis des siècles (millénaires ?) on invente des langages dédiés à telle ou telle discipline pour s'affranchir du flou lié au langage "parlé": ça donne les maths, le solfège, le langage utilisé par des chimistes pour décrire une molécule, les langages de programmation pour les informaticiens, les plans d'architectes, etc... Quand j'écris une ligne de code je ne me demande pas si le compilateur va bien comprendre ce que je veux faire. À la NASA les specs étaient écrites en pseudo code ("Our requirements are almost pseudo-code,” https://archive.is/HX7n4#selection-1303.0-1303.109).
Hier un développeur m'explique pour pour écrire la signature d'une méthode dans un repository spring data il préfère demander à l'IA: l'écriture du prompt est plus longue et forcément plus approximative que l'écriture de la méthode. Personne n'obligeait cette personne à utiliser Spring data, mais dès lors qu'il l'utilise autant qu'il apprenne comment on déclare une méthode. "ajoute une méthode qui retourne les users filtrés d'après leur propriété lastname" est un peu navrant, sans compter les watts et le co2 nécessaire pour traiter ça (heureusement on pourra mettre de nouveaux datacenter au Groenland si besoin...).
Le goût pour l'écriture de code est une question personnelle; personnellement même après 20 ans j'aime toujours ça. Dans "La vie solide" (livre consacré au métier de charpentier) l'auteur cite un charpentier : "si tu ne scies pas pendant 1 semaine tu ne sais plus scier". Ne perd-t-on pas la main si on cesse de coder pendant x semaines, mois ? Vient ensuite l'hésitation à s'y remettre. Et en échange on est devenu dépendant de je ne sais quelle entreprise (anthropic, google, ms, .... ) à laquelle on a envoyé tout notre code tandis qu'on a appris quoi ? Et quand on aime coder on n'a pas forcément une passion pour la relecture de code écrit par quelqu'un d'autre ni pour le boulot de chef de projet.
À moyen-long terme je suis assez sceptique: perte de connaissance, seniors qui partent à la retraite, juniors qui n'apprennent plus à programmer et ne trouvent plus de boulot donc ne seront jamais senior, dette technique qui s'accumule, dépendances vis à vis d'acteurs qui augmenteront leurs tarifs.
Ca n'amuse plus de coder mais ça trouve amusant de prompter....ah !
Quand je vois la tronche d'un prompt pour faire le taf, si c'est ça le métier de codeur demain, ça donne vraiment pas envie
La question c'est surtout à quel moment le "dév ou plutôt l'utilisateur de prompt" va finir par sauter et que l'IA va être directement utilisée par le chef de projet....ou par le mec au dessus ou encore celui au dessus...pour que finalement le boss (avec tout le temps qu'il aura dégagé grâce à ses IA) finissent par être le seul maître à bord en appuyant sur le bouton "IA crée ce que je veux"
Et ensuite le boss sautera parce que le client va directement appuyer sur le bouton
C'est ce que le dév fait au travers de "l’IA sait aussi faire beaucoup de choses pour lesquelles je n’ai pas les compétences", il se passe d'un collègue qui sait, d'une boite qui sait faire
"je considère l’IA comme un assistant, d’intelligence supérieure si je lui explique tout", pourquoi on s'emmerderait avec un employé qui a un assistant, on vire l'employé et on utilise l'IA directement, on gagne encore du temps et surtout de l'argent
"Ne plus coder mais prompter très précisément ses besoins", là on ne s'appellera plus des développeurs mais des prompteurs....bonjour je suis prompteur dans l'informatique....ah moi je suis prompteur au cinéma pour faire des films.....moi je suis prompteur dans la musique....c'est cool on peut s'échanger nos jobs de prompteurs
Bon est ce que l'IA sait creuser un trou pour y enterrer nos métiers, même si les utilisateurs assidus d'IA le font déjà, ça irait vachement plus vite avec l'IA !
"Je m’amuse toujours autant à tester des idées, à envisager 2 ou 3 façons de résoudre un problème et à découvrir ensuite le résultat après quelques minutes", tu pourras faire ça chez toi mais pas au boulot, le boss il a pas envie que tu t'amuses et comme il a les moyens d'utiliser l'IA pour tester, envisager et résoudre les problèmes, t'auras tout ton temps pour t'amuser à l'ancienne chez toi :)
La comparaison avec les luddites est intéressante, justement car les conditions de travail des ouvriers au XIXème en Angleterre étaient épouvantables. Les luddites ne sont pas contre la technologie mais contre une appropriation de celle-ci par une minorité en vue d'exploiter une majorité. Un regard critique sur une technologie et une anticipation des conséquences me semble préférable au "fomo" (fear of missing out"). Le FOMOiste adopte les ORM, les microservices, le nosql, le framework javascript du moment, l'ia, etc... Et après 10 ans ne connaît finalement rien, au mieux est-il moyen partout.
Le développeur luddite est finalement bien plus adepte de la technologie: il s'intéresse à l'implémentation d'une hashmap en java, il lit un plan d'exécution d'une requête SQL, il doit à travers les abstractions, il sait comment fonctionne un garbage collector... et finalement il assume la responsabilité de ce qui est livré en production. Avec plaisir tout au long du chemin et la satisfaction du travail bien fait au moment de livrer.
Bernard Stiegler fait une différence intéressante entre l'emploi et le travail. Être un employé, c'est à dire employé, ou utilisé par un autre, est la définition du prolétaire. Il appuie sur un bouton, ce qu'il fait sera tôt ou tard automatisé. Mais ce n'est pas en cassant la machine qu'on inversera la tendance. Exercer un travail consiste à faire quelque chose qui ne peut pas être automatisé. La frontière de ce qui est automatisable et ce qui ne l'est pas n'est pas fixe, et il me semble intéressant de toujours être du côté du travail plutôt que de l'emploi. De même qu'à un certain niveau de qualité, des habits sont toujours fait à la main.
After two years of vibecoding, I’m back to writing by hand (12 minutes) : https://www.youtube.com/watch?v=SKTsNV41DYg
Un point intéressant de la vidéo: même avec de très bonnes specs, des interrogations apparaissent au moment de coder. De même que lorsque Alex Honnold grimpe El Capitan en free solo, il faut qu'il improvise alors qu'il a étudié la voie mille fois. De même que la réplique d'un acteur dans un film est un peu plus que la lecture du dialogue dans le scénario. C'est le principe de "la carte et le territoire".
"il doit à travers les abstractions". Il voit à travers les abstractions.
Bonjour
J'aimerai juste attirer l'attention la partie CO2: tout le monde se moque t il tellement du devenir de notre climat commun pour que cet aspect ne compte pas?
Qu'une entreprise capitaliste pousse sans états d'âme pour l'usage de la GenAI, bien sûr, évidemment, normal.
Mais en tant qu'individu et citoyen, ne faudrait pas aussi pousser pour un usage compatible avec le climat?
Par ailleurs, je me demande comment les "bas prix" actuels évolueront à l'avenir: clairement les boîtes de GenAI ont tout intérêt à casser les prix actuellement. Avec un peu de chance, elles s'imposeront et, une fois les compétences parties, auront bien plus de latitude pour augmenter les prix. Et tant que dure l'euphorie ou la bulle, pas d'urgence à court terme. Une idée ou une réflexion sur le vrai coût du service proposé?
Enfin, et pour voir l'usage autour de moi (dont le mien), j'ai l'impression qu'on va surtout voir fleurir plein de code dur à maintenir. Genre des tests très verbeux testant mal la fonctionnalité. Sur le coup, ils font plein de lignes, plein de tests, ça semble super. Mais en fait non, c'est bien trop verbeux, fragile et partiel. On a passé plus de temps en revue qu'on en aurait passé à écrire from scratch des tests corrects. Je ne doute pas que des power users, dont sans doute le Touilleur Express, font des choses de qualité, mais de là à dire que ce sera la norme... Au moins quand on écrit soi même le code on évite de pondre 1000 lignes là où 100 suffisent. Mais vu que les lignes sont pondues "gratuitement", cette incitation disparait et 3/4 des dév ne veulent que pondre le code qui leur permettra de passer à autre chose...