On y est. Le code est généré par des outils de génération de code, à base de prompts. Nous sommes au début de 2026. Les développeurs ouvrent un terminal, tapent « Claude Code », et génèrent du code avec des outils de GenAI.
Je vous recommande la lecture passionnante du rapport « The 2026 State of Software Delivery Report » publié par CircleCI. C’est une mine d’or car il observe presque 28 millions de pipeline CircleCI… et tente d’analyser l’impact des outils comme Claude Code, Codex CLI ou Cursor sur notre industrie. Il existe d’autres rapports comme « Engineering Team Velocity » de Greptile, qui complète ce que l’on observe déjà dans nos équipes.
Est-ce que les outils de generative coding, ou GenAI permettent de générer plus de lignes de code ? Oui. Les tailles des pull-requests augmentent. Encore faut-il comprendre que l’indicateur du nombre de lignes de code, est lui-même très critiquable. Compter le nombre de lignes pour mesurer la productivité d’un développeur est d’une faiblesse intellectuelle… C’est très bien expliqué dans « Lines of Code Are Back (And it’s worse than before) » par Allan Macgregor.
L’arrivée d’outils de génération de code comme Claude Code va entraîner des changements au sein des équipes de développement. D’abord, vous observerez que tout le monde ne va pas embarquer immédiatement, pour différentes raisons. Après 5 mois de mise à disposition de Claude Code dans mon entreprise, il y a eu 147 utilisateurs actifs en février 2026, sur un total de 280 personnes. Et certains ont utilisé l’outil plusieurs heures par jour, alors que d’autres ne s’en servent que de temps en temps. Cursor est progressivement abandonné, les développeurs migrent vers Claude Code. On passe de l’aire de la complétion intelligente… à l’écriture complète via des outils de GenAI.
L’une de mes observations ces derniers mois, c’est que les personnes qui ne veulent pas/n’ont pas le temps/refusent d’utiliser ces outils… les subissent malgré elles. Cela se matérialise par un développeur junior qui génère 1000 lignes de code en une demi-journée, mais qui entraîne une revue de code de deux jours, par un développeur plus expérimenté. La revue ne s’est pas bien passée. Beaucoup de code n’était pas aligné avec les pratiques historiques des développeurs sur ce repository. L’IA déborde déjà partout. Que ce soit sur le code, sur la documentation, sur nos channels Slacks, sur les présentations, sur des migrations de code ou autre… il y en a partout.
Ce que j’ai aussi observé : les outils de génération de code ont tendance à déplacer la charge de travail, si l’on est pas vigilant. Vous allez diviser par deux votre temps de développement, mais peut-être augmenter le temps de revue de code, si vous n’y prenez pas garde. Ou le temps de mise en prod, car il y a maintenant 50 PR à merger par heure… au lieu de 10 avant. Ou alors en amont : les développeurs vont plus vites, et le Product Manager doit lui-même s’adapter à la charge, pour fournir toujours des tickets à implémenter. Claude Code est un outil qui déplace les goulets d’étranglement, que vous le vouliez ou non.
Greptile montre ici que le volume moyen du nombre de lignes dans les Pull-requests a augmenté de 33% de mars à novembre 2025, passant en moyenne de 57 à 76 lignes modifiées. Le nombre de lignes par développeur et par mois, lui, passe de 4450 à 7839 lignes par mois.
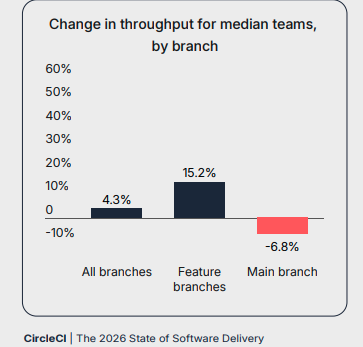
Le rapport de CircleCI est très intéressant car il montre que le nombre de « succesful merge » sur les branches main a diminué de 6.8% sur 12 mois… alors que le nombre de PRs a lui, augmenté de 15%. Visiblement les revues de code, la validation et la livraison du code, à l’aire de l’IA, n’est pas si productive que cela.
Se concentrer uniquement sur le volume de lignes de code est une erreur. Il faut s’intéresser plutôt aux nombres de validation/intégration et mise en production, rapportés au nombre de développeurs dans une entreprise. Et encore…
Un peu plus loin, le rapport de CircleCI montre que le taux de build successful sur la branche main est tombé de 80% à 70% en une année. Autrement dit : 3 builds sur 10 ne sont pas verts sur la branche main. Cela ralentit alors forcément le nombre de PRs mise en production. Est-ce que c’est directement lié à l’IA ? Cela me semble difficile à croire, l’IA aurait bon dos de prendre la responsabilité de tout ce qui se passe… Mais bon, c’est intéressant.
Le nombre de lignes n’est qu’un indicateur de volume. Certainement pas de la qualité du travail. Si vous générez des tests unitaires suffisants et nécessaires, cela permet ensuite à Claude Code lui-même de tester votre code : ok ! Mais si vous générez des tests pour vérifier si un getter/setter fonctionne… alors la quantité ne sert à rien.
Pour ce prémunir de cela, les développeurs sont maintenant obligés de verbaliser/écrire leurs règles. Ce qui se passait de développeur en développeur de façon empirique… doit maintenant être écrit dans un fichier CLAUDE.md ou AGENTS.md pour que les LLM en tiennent compte. Un agent n’ayant en plus aucune mémoire, il ne se corrigera pas tant que vous n’aurez pas fait l’effort de lui dire « ce qui est correct » ou « ce qui n’est pas valide ».
Il va y avoir une tension entre les personnes qui utilisent les outils de GenAI, et les autres. C’est obligé. Chez nous, cela se passe par des discussions animées (mais professionnelles) sur l’idée de rajouter des fichiers Markdown… uniquement pour les Agents. Faut-il prévoir un fichier « ARCHITECTURE.md » ? Mais cela va plus loin : les commentaires dans le code. Les LLMs bénéficient des commentaires dans le code, et vont en tenir compte dans leur contexte. Mais les développeurs (surtout ceux qui ne connaissent pas encore le fonctionnement d’un Claude Code), vont avoir tendance à refuser l’ajout de ces commentaires dans les pull-requests. Le motif ? On ne le faisait pas pour les humains… pourquoi le faire pour les LLMs ?
Ce que j’en pense : un peu plus de documentation facilite la lecture. Cela réduit aussi l’usage des tokens, accélère le travail de Codex CLI, de Copilot CLI ou Claude Code. Je suis donc en faveur de rajouter de la documentation dans le code, et dans le repository. J’ai tendance à garder le fichier CLAUDE.md très petit, et à référencer d’autres fichiers. Je vous déconseille de tenter d’avoir un fichier CLAUDE.md pour tous vos projets. C’est une erreur. Au contraire, le fichier doit être ultra adapté au contexte métier de votre projet. Ce n’est pas qu’un fichier pour coder.
Enfin, j’aimerais voir si vous me suivez dans une vision qui va peut-être en surprendre quelques-uns.
J’imagine que demain, j’ouvrirai une pull request, mais que je ne mettrai qu’un prompt, dans ma PR. Mon prompt détaillé aura été crafté en local, à partir d’une discussion entre l’agent et moi-même. J’aurai travaillé et préparé un plan ultra détaillé (similaire à ce que la fonction de planification de Claude Code nous propose en ce moment, début 2026).
Bref je prépare mon plan, je l’envoie vers le serveur central, sous la forme d’une pull-request. Le prompt est pris par un VM avec un Agent, qui sélectionne le modèle adapté à ma demande. Ensuite l’agent déroule le plan et prépare en retour une autre pull-request… de changement de code. Il exécutera cependant auparavant différents outils comme une revue de code, une revue de sécurité, la vérification des tests unitaires et des tests d’intégration. Enfin, il me préparera pour moi un plan détaillé de revue. Je n’aurai alors plus qu’à m’assurer que le résultat est ok.
Cela permettra d’externaliser, dans un premier temps, des tâches de développement secondaires. J’imagine très bien que le langage de programmation n’aura même plus d’importance. Que ce soit du Java, du Python, du Kotlin ou autre… on s’en fichera.
Demain, nous ferons des pull-requests avec nos prompts ou nos plans détaillés.
Ce n’est pas « Generative Coding » mais « Generative Prompting »…
2 likes

Leave a Comment