Aujourd’hui, voyons comment intégrer ElasticSearch dans un projet Big Data, avec Apache Hadoop. Pour cela, je vais utiliser Elasticsearch for Apache Hadoop, un simple JAR, et un peu de Scala avec Apache Spark. Mais avant cela, quelques lignes sur chacun de ces outils.
Apache Hadoop
Hadoop est un projet open-source créé par Doug Cutting et Mike Cafarella, qui fait partie de la fondation Apache depuis 2009. C’est un framework Java, qui permet de construire des applications de traitements répartis et de stocker des volumes importants de données, ce que l’on appelle généralement Big Data (Les 3 Grands « V »).
Hadoop est un écosystème, composé de 4 projets principaux. La partie stockage répartie est adressée par HDFS. Le coeur du système est regroupé autour d’Hadoop Common. La partie traitement distribué est organisé autour de MapReduce. Enfin l’orchestration et la configuration des tâches est faite par YARN. Au delà d’Hadoop, de nombreux projets complètent le framework, selon vos besoins. Ambari facilite par exemple l’administration via une console Web. Pig, Tez, Avro, Hive, HBase… l’éco-système autour d’Hadoop est aujourd’hui mature et très puissant.
Ce projet est certainement amené à structurer les développements d’une bonne partie de l’industrie logiciel, dans le monde du Big Data et du Machine Learning. Or il n’est pas rattaché à un éditeur historique comme IBM ou Oracle. De nouveaux éditeurs comme Hortonworks et Cloudera ont créé des solutions complémentaires, au dessus d’Hadoop. L’impact en 2016 de ce projet est déjà visible : aujourd’hui on recrute des développeurs (H/F) Big Data, des ingénieurs, des DataScientists capables de faire du R, du Python et du Scala.
Elasticsearch
Elasticsearch est la solution la plus puissante et la plus pratique dès lors qu’il s’agit de mettre un moteur de recherche sur une application. L’outil permet aussi de construire des tableaux de bord, de faire des recherches par agrégations, et se programme facilement dès lors que l’on utilise une librairie tierce.
Pourquoi Elasticsearch et Hadoop ?
Hadoop adresse le problème du stockage, de la répartition des données sur plusieurs machines, et vous permettra de faire des traitements parallèles. Mais cela reste lent. Il faut vraiment voir cet ensemble comme un système de fichiers distribués. Or vous ne pouvez pas facilement construire une application Web directement sur des données « brutes ». Dans ce type d’architecture, il est intéressant d’avoir 2 environnements (2 layers) différents. Elasticsearch est parfait dès lors qu’il s’agit de construire une application de visualisation de la donnée. Plutôt que d’avoir un seul environnement de stockage, nous allons introduire un « Speed Layer » dans notre architecture.
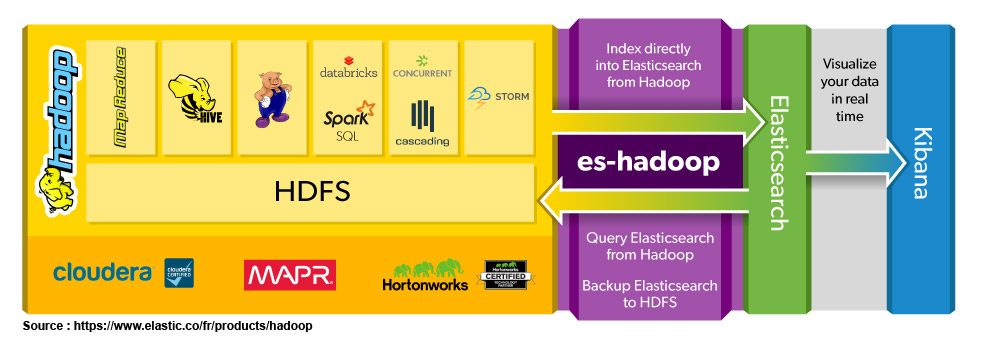
Elasticsearch est une forme de base NoSQL, avec son propre modèle d’objet. Il est donc fréquent d’avoir un modèle de données différent du modèle de stockage sur HDFS. Je vais repenser mes objets et les relations entre mes entités complètement différemment sur ES. Tout sera optimisé et modélisé selon ma problématique de recherche et d’affichage. La séparation entre le stockage et la restitution simplifiera le code.
Plus globalement, il est assez fréquent aujourd’hui d’avoir plusieurs types de moteur de bases de données sur une seule application. Le CFP de Devoxx par exemple utilise Redis comme base NoSQL principale, et ElasticSearch pour la recherche de speaker et de proposition. Pourquoi avoir remis ES ? Car celui-ci est capable de faire de l’indexation full-text, de calculer des statistiques rapidement, et se prête particulièrement bien à la partie Recherche et Stats de l’outil. A contrario, il n’est pas aussi pratique que Redis, et il est plus efficace d’utiliser Redis comme base de données principale. Si vous voulez comprendre comment on peut construire un site avec 2 bases de 17 Gb, je vous invite à relire un de mes articles sur Redis.
Spark-shell et Elasticsearch
Spark permet de travailler sur des données réparties sous la forme de bloc RDD (Resilient Distributed Dataset). Lorsque vous devez effectuer des traitements sur de gros fichiers, Spark va distribuer les tâches sur plusieurs machines, puis exécuter des fonctions pour enfin rassembler le résultat. Côté clustering, Spark dispose de son propre système, mais fonctionne avec Mesos ou YARN. Côté stockage, Spark s’interface avec HDFS, Cassandra, Map-R, S3 et d’autres systèmes de stockage. Fin 2016, 2 versions de Spark sont disponibles. D’une part la 1.6 sortie mi-2016 qui reste la plus utilisée (et la plus stable). D’autre part la nouvelle version 2.0, qui a reçu plus de 2500 contributions de 300 développeurs… Big Data mais aussi Big community.
Pour mon exemple, j’ai utilisé la machine virtuelle Sandbox d’Hortonworks, qui permet d’avoir une image Virtual Box « prête à fonctionner ». J’aurai aimé utiliser Docker, mais au moment d’écrire ces lignes, les images Docker d’HDP sont trop expérimentales pour moi. Bref si vous voulez découvrir HDP, récupérez la sandbox et démarrez la bête sur votre machine (je vous conseille d’avoir au moins 16 Go de mémoire vive sur votre machine de dev comme moi).
Environnement de développement
Pour cet exercice, j’ai un serveur Elasticsearch 2.4 démarré via Docker, accessible de ma machine hôte (un Mac) et pour l’instant configuré en dehors d’un cluster. J’ai d’autre part ma machine Virtual Box avec la Sandbox Hortonworks. Pour que Spark puisse discuter avec le serveur Elasticsearch, il va falloir qu’il « sorte » de la VM, pour aller sur ma machine, sur laquelle Docker a re-routé les ports d’ES. Euh… c’est un peu compliqué non ?
Mais non… un schéma et tout sera plus clair :
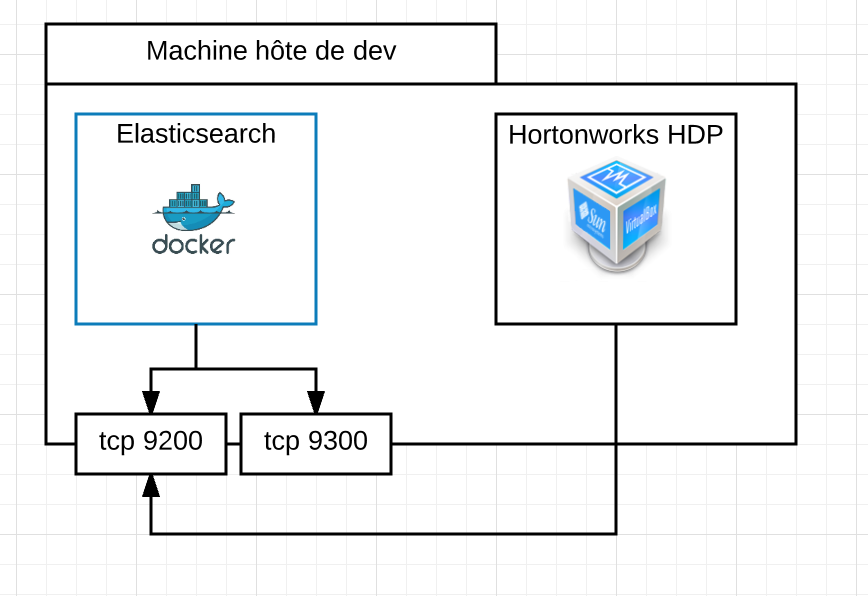
Du côté de la Sandbox d’Hortonworks, il faudra télécharger Elastic-hadoop, distribué sous la forme de plusieurs JARs, et copier ces fichiers vers la sandbox :
nicolas@mac > scp -P 2222 elasticsearch-hadoop-2.4.0.zip root@sandbox.local:/tmp
A noter que sur la Sandbox, vous pouvez utiliser le compte root par défaut (mot de passe : hadoop) ou le compte maria_dev. J’ai modifié volontairement mon fichier /etc/hosts sur mon Mac. pour y ajouter sandbox.local (=127.0.0.1)
Connectez-vous via SSH sur la Sandbox, le serveur SSH écoute sur le port 2222. Placez-vous dans le répertoire /tmp, puis ensuite décompressez l’archive zip. Il existe d’autres façons d’installer elasticsearch-hadoop, ainsi que des plugins pour Spark, mais ici nous allons utiliser la version distribuée par Elastic.
Préparation de l’environnement sur la Sandbox
Pour cette exercice, notre objectif est de lire un gros fichier CSV via Spark-shell puis de l’indexer sur Elasticsearch. A titre d’exemple, nous allons travailler avec les horaires des transports en commun en Ile-de-France. Téléchargez le fichier stif_gtfs.zip à partir du site OpenData du STIF, puis placez-le sur la Sandbox dans un répertoire de travail temporaire.
nicolas@fountainhead2 ~/Downloads> scp -P 2222 stif_gtfs.zip root@sandbox.local:/tmp
root@sandbox.local's password: hadoop
stif_gtfs.zip........... 100% 47MB 46.8MB/s 00:01
Une fois le fichier sur la Sandbox, il faut alors décompresser l’archive, puis copier les fichiers vers HDFS, pour qu’ils soientt accessible. Connectez-vous sur la Sandbox, puis utilisez hadoop fs en ligne de commande :
<span class="s1"><b>nicolas</b></span><span class="s2">@</span><span class="s3"><b>fountainhead2</b></span> <span class="s1">~/Downloads</span> <span class="s4">[130]</span><span class="s2">> </span><span class="s5">ssh</span> <span class="s6">root@sandbox.local</span> <span class="s6">-p</span> <span class="s6">2222</span><span class="s6">root@sandbox.local's password: </span><span class="s6">Last login: Fri Sep<span class="Apple-converted-space"> </span>9 20:28:28 2016 from 10.0.2.2</span><span class="s6">[root@sandbox ~]# mkdir dev_nicolas && cd dev_nicolas</span>[root@sandbox dev_nicolas]# unzip /tmp/stif_gtfs.zip[root@sandbox dev_nicolas]# hadoop fs -mkdir /tmp/test-spark[root@sandbox dev_nicolas]# hadoop fs -copyFromLocal /root/dev_nicolas/stops.txt <strong><span style="color: #008000;">/tmp/test-spark/</span></strong>Le répertoire /tmp/test-spark est un répertoire sur le système de fichier HDFS. Ces commandes permettent de placer un fichier sur le système HDFS, afin de pouvoir l’utiliser ensuite avec Spark.
Spark-shell et CSV
Je démarre Spark-shell en ayant le JAR d’elasticsearch-hadoop sous la main de cette façon :
[root@sandbox dist]# spark-shell --jars elasticsearch-hadoop-2.4.0.jar \
--conf spark.es.nodes="172.20.20.2" \
spark.es.nodes.wan.only="true" \
spark.es.nodes.resolve.hostname="false" \
--packages com.databricks:spark-csv_2.11:1.5.0
En rose : il s’agit de l’IP de ma machine, de mon Mac, dans le réseau. C’est de cette façon que spark va découvrir et discuter avec ma machine hôte, sur laquelle ensuite Docker re-route le port 9200. A noter que j’ai désactivé la résolution des nodes. L’option packages permet « à la Maven » de tirer une dépendance afin d’avoir un parser CSV dans mon shell spark.
Après avoir validé, Spark démarre, et le shell (sbt) attend vos premières lignes en Scala. Nous allons importer les librairies ES, puis déclarer une Case class pour définir un arrêt (voir la documentation du référentiel du STIF ici)
scala> import org.elasticsearch.spark._
import org.elasticsearch.spark._
scala> case class Stops(stop_id:String,stop_name:String,stop_desc:String,stop_lat:String,stop_lon:String,zone_id:String,stop_url:String,location_type:Int,parent_station:String)
defined class Stops
scala>
Nous pouvons maintenant créer notre contexte Spark, et utiliser le fichiers stops.txt que nous avions placé sur /tmp/test-spark/
scala> val df = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/tmp/test-spark/stops.txt","header"->"true"))
[.... beaucoup de lignes de logs] 16/09/09 20:38:40 INFO Executor: Running task 0.0 in stage 4.0 (TID 4) 16/09/09 20:38:40 INFO HadoopRDD: Input split: hdfs://sandbox.hortonworks.com:8020/tmp/test-spark/stops.txt:0+2189771 16/09/09 20:38:40 INFO Executor: Finished task 0.0 in stage 4.0 (TID 4). 2193 bytes result sent to driver 16/09/09 20:38:40 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 4) in 15 ms on localhost (1/1) 16/09/09 20:38:40 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool 16/09/09 20:38:40 INFO DAGScheduler: ResultStage 4 (first at CsvRelation.scala:269) finished in 0,014 s 16/09/09 20:38:40 INFO DAGScheduler: Job 4 finished: first at CsvRelation.scala:269, took 0,023861 s
df: org.apache.spark.sql.DataFrame = [stop_id: string, stop_name: string, stop_desc: string, stop_lat: string, stop_lon: string, zone_id: string, stop_url: string, location_type: string, parent_station: string]
scala >
Et voilà
Voyons combien de lignes nous avons dans ce fichier CSV :
scala > df.count() [... un paquet de logs...] 59374
Nous sommes dans un univers Scala, et nous pouvons commencer à écrire quelques lignes simples. Par exemple, combien d’arrêts de bus ou de métro s’appellent « MAIRIE » ?
scala> val stopsWithMairie = df.map(line=>line(1)).filter(s=> s.equals("MAIRIE")) stopsWithMairie: org.apache.spark.rdd.RDD[Any] = MapPartitionsRDD[43] at filter at <console>:39 scala> stopsWithMairie.count 135
Jacqueline, elle fait pareil et directement dans Excel
A cette étape, vous allez me dire que Jacqueline avec son fichier Excel et ses filtres fait pareil.
Oui mais Jacqueline elle ne fait pas du Big Data. Tout ce que vous avez vu est particulièrement à l’aise lorsque les données sont trop importantes pour être ouvert sur le poste de bureautique de Jacqueline. Oui, la cruelle vérité c’est que le Big Data commence où les limites matérielles de Jacqueline se trouvent.
Et Elasticsearch alors ?
Il faut maintenant transformer notre ensemble de RDD en une collection prête à être indexer. Là je vous avoue que je ne connais pas encore assez les concepts du Dataframe. Mais bon, allons-y. Ecrivons une fonction de transformation qui va retourner une liste de « Stops » (notre case class définie plus tôt)
scala> val dataReadyForES = df.map(line=> Stops(| line(0).toString,| line(1).toString,| line(2).toString,| line(3).toString,| line(4).toString,| line(5).toString,| line(6).toString,| line(7).toString.toInt,| line(8).toString| ))dataReadyForES: org.apache.spark.rdd.RDD[Stops] = MapPartitionsRDD[44] at map at <console>:40
scala>Nous avons maintenant créé un RDD de Stops, qui n’attend plus que notre ordre de persistence.
scala> dataReadyForES.saveToEs("captaindash/gtfs_test_stops")[un bon paquet de logs... musique d'attente... et bam ça marche]
scala>Conclusion, ouverture et où l’on reparle de Jacqueline
Pourquoi utiliser HDFS ? Et comment tu gères ton index ES ? Et comment tu fais un mapping propre sur ES ? Il n’existe pas de plugin ES ? Et…
Je déconseille tout d’abord de jouer avec des CSV et de parser/splitter le contenu « à l’ancienne ». Dès lors que vous aurez des données à escaper, votre code ne marchera pas. Donc please, utilisez les outils de la stack Spark pour travailler avec des fichiers CSV.
Ici nous sommes dans un environnement de développement. Dans la vraie vie avec un vrai projet, vous utiliserez certainement un cluster Hadoop dédié. Pour mon projet, j’ai aussi configuré mon Elasticsearch en data-node, et j’utilise un master distant, qui est celui qui « mange » vraiment mes indexations.
Bref ce que vous avez vu m’a demandé quelques heures, et me permet d’indexer un fichier « tel quel » vers ES. La réalité est différente. Nous serons plus amené à écrire des programmes ou des scripts Spark en Scala, plus complexes, pour adapter le modèle et ne pas indexer « tels quels » nos fichiers. Mais nous verrons cela dans un prochain article. On en garde sous le pied.
Ressources
La sandbox d’Hortonworks : http://fr.hortonworks.com/products/sandbox/
ElasticHadoop : https://www.elastic.co/fr/products/hadoop
Voir aussi mon article précédent sur Docker + ElasticSearch publié sur le Touilleur Express
Tutorial sur Hadoop et HDFS en ligne de commande
La release note de Spark 2.x, mais je vous conseille de travailler en 1.6.2 pour l’instant (on est fin 2016 là)
Crédit photo : http://negativespace.co/photos/traffic-stock-photo/
0 no like





Commentaires récents